Dynamic LOV with Pipeline function
Von Tobias Arnhold →
1.18.2018
A new year brought me some new tasks. I had to take over a generic Excel import and the customer wanted some extension by checking if the join on the master tables were successful.
Unfortunate we were talking about a generic solution which meant that all the configuration was saved inside tables including the LOV-tables which were saved as simple select statements.
Goal:
Show all import rows/values which were not fitting towards the master data.
How did I fix it?

Source of LOV data:

Source of import data:
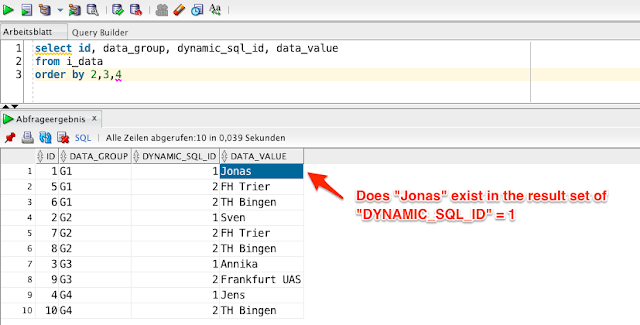
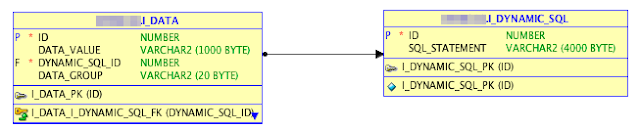
I made a little abstract data model so that you understand what I mean:
I have two tables "I_DATA" including the values from the import and "I_DYNAMIC_SQL" including the LOV statements.
1. Fast
2. Easy to understand
3. Not tons of code
What I needed was some kind of EXECUTE IMMEDIATE returning table rows instead of single values. With pipeline functions I was able to do it:
Now I just had to create a SQL statement doing the job for me:
Result:

Unfortunate we were talking about a generic solution which meant that all the configuration was saved inside tables including the LOV-tables which were saved as simple select statements.
Goal:
Show all import rows/values which were not fitting towards the master data.
How did I fix it?

Source of LOV data:

Source of import data:

I made a little abstract data model so that you understand what I mean:
I have two tables "I_DATA" including the values from the import and "I_DYNAMIC_SQL" including the LOV statements.

-- ddl
CREATE TABLE "I_DYNAMIC_SQL"
( "ID" NUMBER NOT NULL ENABLE,
"SQL_STATEMENT" VARCHAR2(4000),
CONSTRAINT "I_DYNAMIC_SQL_PK" PRIMARY KEY ("ID")
USING INDEX ENABLE
) ;
CREATE TABLE "I_DATA"
( "ID" NUMBER NOT NULL ENABLE,
"DATA_VALUE" VARCHAR2(1000),
"DYNAMIC_SQL_ID" NUMBER,
"DATA_GROUP" VARCHAR2(20),
CONSTRAINT "I_DATA_PK" PRIMARY KEY ("ID")
USING INDEX ENABLE
) ;
-- data
REM INSERTING into I_DATA
SET DEFINE OFF;
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (1,'Jonas',1,'G1');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (2,'Sven',1,'G2');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (3,'Annika',1,'G3');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (4,'Jens',1,'G4');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (5,'FH Trier',2,'G1');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (6,'TH Bingen',2,'G1');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (7,'FH Trier',2,'G2');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (8,'TH Bingen',2,'G2');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (9,'Frankfurt UAS',2,'G3');
Insert into I_DATA (ID,DATA_VALUE,DYNAMIC_SQL_ID,DATA_GROUP) values (10,'TH Bingen',2,'G4');
REM INSERTING into I_DYNAMIC_SQL
SET DEFINE OFF;
Insert into I_DYNAMIC_SQL (ID,SQL_STATEMENT) values (1,'select d,r from (
select ''Jonas'' as d, 1 as r from dual union all
select ''Sven'' as d, 2 as r from dual union all
select ''Jens'' as d, 3 as r from dual union all
select ''Annika'' as d, 4 as r from dual
)');
Insert into I_DYNAMIC_SQL (ID,SQL_STATEMENT) values (2,'select d, r
from (
select ''FH Trier'' as d, 1 as r from dual
union all
select ''TH Bingen'' as d, 2 as r from dual
)');
It actually took some time to find a solution fitting my needs. 1. Fast
2. Easy to understand
3. Not tons of code
What I needed was some kind of EXECUTE IMMEDIATE returning table rows instead of single values. With pipeline functions I was able to do it:
create or replace package i_dynamic_sql_pkg as
/* LOV type */
type rt_dynamic_lov is record ( display_value varchar2(4000), return_value number );
type type_dynamic_lov is table of rt_dynamic_lov;
function get_dynamic_lov (
p_lov_id number
) return type_dynamic_lov pipelined;
end;
create or replace package body i_dynamic_sql_pkg as
/* global variable */
gv_custom_err_message varchar2(4000);
/* Function to return dynamic lov as table */
function get_dynamic_lov (
p_lov_id number
) return type_dynamic_lov pipelined is
row_data rt_dynamic_lov;
type cur_lov is ref cursor;
c_lov cur_lov;
e_statement_exist exception;
v_sql varchar2(4000);
begin
-- 'Exception check - read select statement';
select
max(sql_statement)
into
v_sql
from i_dynamic_sql
where id = p_lov_id;
-- 'Exception check - result';
if v_sql is null
then
gv_custom_err_message := 'Error occured. No list of value found.';
raise e_statement_exist;
end if;
-- 'Loop dynamic SQL statement';
open c_lov for v_sql;
loop
fetch c_lov
into
row_data.display_value,
row_data.return_value;
exit when c_lov%notfound;
pipe row(row_data);
end loop;
close c_lov;
exception
when e_statement_exist then
rollback;
/*
apex_error.add_error(
p_message => gv_custom_err_message
, p_display_location => apex_error.c_inline_in_notification
);
*/
raise_application_error(-20001, gv_custom_err_message);
when others then
raise;
end;
end;
Now I just had to create a SQL statement doing the job for me:
-- ddl
select
da.data_group,
da.data_value,
/* check if a return value exist */
case
when lov.display_value is not null
then 'OK'
else 'ERROR'
end as chk_lov_data_row,
/* apply error check for the whole group */
case
when min(case
when lov.display_value is not null
then 1
else 0
end) over (partition by da.data_group)
= 0
then 'ERROR'
else 'OK'
end as chk_lov_data_group
from i_data da
/* Join on my pipeline function including the dynamic sql id */
left join table(i_dynamic_sql_pkg.get_dynamic_lov(da.dynamic_sql_id)) lov
on (da.data_value = lov.display_value)
order by da.data_group, da.dynamic_sql_id, da.data_value;
Result: